Android内存管理(JVM 、DVM(dalvik) 、ART联系与区别)
Android内存管理(JVM 、DVM(dalvik) 、ART简单介绍)
本文不对JVM 、DVM(dalvik) 、ART这三者做具体的分析。只是从内存管理的角度来介绍下三者的区别和联系。
Java是一种编译+解释的语言。最主要的目的是跨平台,为了实现跨平台,就决定了不能像 c,c++ 那样直接把源代码编译成可执行文件,因为不同cpu,不同操作系统的指令封装格式是不一样的。java编译成的字节码文件与硬件和操作系统无关,这是跨平台基础,然后具体执行,再用各自平台解释器,解释成本地机器码。
JVM
JVM本质上就是一个软件,是计算机硬件的一层软件抽象,在这之上才能够运行Java程序,JAVA在编译后会生成类似于汇编语言的.class字节码文件,与C语言编译后产生的汇编语言不同的是,C编译成的汇编语言会直接在硬件上跑,但JAVA编译后生成的.class字节码是在JVM上跑,需要由JVM把字节码翻译成机器指令,才能使JAVA程序跑起来。
JVM运行在操作系统上,屏蔽了底层实现的差异,从而有了JAVA吹嘘的平台独立性和Write Once Run Anywhere。根据JVM规范实现的具体虚拟机有几十种,主流的JVM包括Hotspot、Jikes RVM等,都是用C/C++和汇编编写的,每个JRE编译的时候针对每个平台编译,因此下载JRE(JVM、Java核心类库和支持文件)的时候是分平台的,JVM的作用是把平台无关的.class里面的字节码翻译成平台相关的机器码,来实现跨平台。
Java程序执行流程:
从上图可以看到Java虚拟机与java语言没有什么必然联系,它只与特定的二进制文件:Class文件有关。
数据类型
Java虚拟机与Java语言的数据类型相似,可以分为两类:基本类型和引用类型。Java虚拟机希望编译器在编译期间尽可能的完成类型检查,使得虚拟机在运行期间无需进行类型检查操作。
运行时数据区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为不同的数据区域,数据区域分别为
程序计数器
Java虚拟机栈
本地方法栈
Java堆
方法区
1. 程序计数器
程序计数器(Program Counter Register),可以看做当前线程所执行的字节码的行号指示器(其实就是记录代码执行到了哪里)。
特点如下:
线程私有;
占用内存空间较小;
若线程执行的是 Java 方法,记录的是虚拟机字节码指令地址;若执行的是本地(Native)方法,则为空(Undefined);
该区域是唯一一个在《Java 虚拟机规范》中规定无任何 OutOfMemoryError 的区域。
主要作用:记录线程执行到了哪里。
2. Java 虚拟机栈
Java 虚拟机栈(Java Virtual Machine Stacks):Java 方法执行的线程内存模型。
每个方法被执行时,虚拟机栈都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每个方法从被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。其中局部变量表包括:
Java 虚拟机基本数据类型(8 种)
对象引用(reference 类型,可能是一个指向对象起始地址的指针)
returnAddress
这些数据类型在局部变量表中的存储空间以局部变量槽(Slot)表示,其中 long 和 double 占用两个槽,其他类型占用一个槽。局部变量表所需内存空间在编译期完成分配,当进入一个方法时,该方法需要在栈帧中分配多大的局部变量空间是完全确定的,运行期间不会改变其大小。
虚拟机栈的特点:
线程私有;
生命周期与线程相同;
两类异常
线程请求的栈深度大于虚拟机所允许的深度时抛出 StackOverflowError 异常;
栈扩展时无法申请到足够的内存时抛出 OutOfMemoryError 异常。
主要目的:Java 方法执行的线程内存模型。
3. 本地方法栈
本地方法栈(Native Method Stacks)与 Java 虚拟机栈作用类似。二者区别:
Java 虚拟机栈为 JVM 执行 Java 方法(字节码)服务;
本地方法栈为 JVM 使用到的本地(Native)方法服务。
异常与 Java 虚拟机栈相同。
主要目的:Native 方法执行的线程内存模型。
4. Java 堆
对多数应用来说,Java 堆(Java Heap)是 JVM 管理的内存中最大的一块。
唯一目的:存放对象实例(【几乎所有】的对象实例都在这里分配内存)。
《Java 虚拟机规范》描述:所有对象实例及数组都应在堆上分配。
而从实现角度看,由于即使编译技术(尤其是逃逸分析技术的日渐强大),"栈上分配"等手段使得对象并非完全在堆上分配。
特点:
线程共享
虚拟机启动时创建
PS: "新生代"、"老年代"、"Eden 区"等一系列对堆的区域划分,只是部分垃圾收集器的一些共性或设计风格,而非虚拟机的固有内存布局,更非《Java 虚拟机规范》的划分。
将 Java 堆细分的目的只是为了更好地回收内存,或者更快地分配内存。
5. 方法区
方法区(Method Area):用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据,该区域也是线程共享的。又称"非堆"。
与方法区联系密切的一个概念是"永久代",下面简要介绍。
永久代
"永久代(Permanent Generation)",可以理解为 JDK 1.8 之前 HotSpot 虚拟机对《Java 虚拟机规范》中"方法区"的实现。从 JDK 1.6、1.7 到 1.8+,HotSpot 虚拟机的运行时数据区变迁示意图如下:
HotSpot VM JDK 1.6 的运行时数据区示意图如下:
JDK 1.7 中,将 1.6 中永久代的字符串常量池和静态变量等移到了堆中,如下(虚线框表示已移除):
而到了 JDK 1.8,则完全废弃了"永久代",改用了在本地内存中实现的"元空间(Metaspace)",将 JDK 1.7 中永久代剩余的部分(主要是类型信息)移到了元空间,如下(虚线框表示已移除):
从上面几张图可以看出永久代和元空间的主要区别有以下两点:
存储位置不同
永久代是 JVM 内存的一部分,元空间在本地内存中(JVM 内存之外);
永久代使用不当可能导致 OOM,元空间一般不会。
存储内容不同:元空间存储的是「类型信息」(即类的元信息),而永久代除了类型信息,还包括「字符串常量池」和「静态变量」等(可以理解为元空间是永久代拆分出来的一部分)。
那么问题来了:为什么要把永久代替换为元空间呢?
原因大概有以下几点:
Oracle 收购了两种 JVM:HotSpot VM 和 JRockit VM,并且想要将它们整合,但二者方法区实现差异较大;
字符串存在永久代中,容易出现性能问题和 OOM;
类及方法的信息大小较难确定,永久代大小难以确定:太小易导致永久代溢出,太大则易导致老年代溢出(JVM 内存是有限的,此消彼长);
永久代会为垃圾回收带来不必要的复杂度,且回收效率较低("性价比"低)。
以下6 7 不再jvm内存运行模型中,但对内存管理过程中需要注意,因为他们经常导致oom。
6. 运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。
Class 文件中除了有类的版本、字段、方法、接口等描述外信息,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
相比于 Class 文件常量池的一个重要特性是「动态性」,运行期间也可以将新的常量放入池中(例如 String 类的 intern() 方法)。
可能产生的异常:OutOfMemoryError。
7. 直接内存
直接内存(Direct Memory)并非虚拟机运行时数据区的一部分,也非《Java 虚拟机规范》定义的内存区域。但该部分内存被频繁使用(例如 NIO),而且可能导致 OutOfMemoryError。
NIO(New input/output)是JDK1.4中新加入的类,引入了一种基于通道(channel)和缓冲区(buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过堆上的DirectByteBuffer对象对这块内存进行引用和操作。
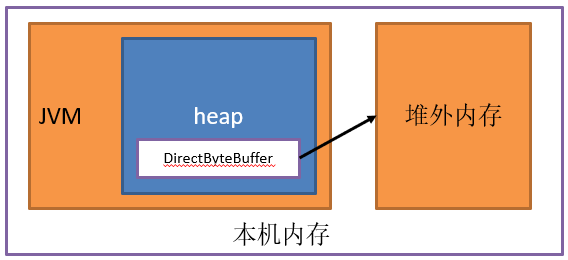
可以看出,直接内存的大小并不受到java堆大小的限制,甚至不受到JVM进程内存大小的限制。它只受限于本机总内存(RAM及SWAP区或者分页文件)大小以及处理器寻址空间的限制(最常见的就是32位/64位CPU的最大寻址空间限制不同)。
直接内存出现OutOfMemoryError的原因是对该区域进行内存分配时,其内存与其他内存加起来超过最大物理内存限制(包括物理的和操作系统级的限制),从而导致OutOfMemoryError。另外,若我们通过参数“-XX:MaxDirectMemorySize”指定了直接内存的最大值,其超过指定的最大值时,也会抛出内存溢出异常。
GC
GC主要做了两个工作,一个是内存的划分和分配,一个是对垃圾进行回收。
垃圾标记算法
关于对垃圾进行回收,被引用的对象是存活的对象,而不被引用的对象是死亡的对象也就是垃圾,GC要区分出存活的对象和死亡的对象,也就是垃圾标记,并对垃圾进行回收。目前有两种垃圾标记算法,分别是引用计数算法和根搜索算法,这两个算法都和引用有些关联。
引用: 在JDK1.2之后,Java将引用分为强引用、软引用、弱引用和虚引用。
强引用: 当我们new一个对象时就是创建了一个具有强引用的对象,如果一个对象具有强引用,垃圾收集器就绝不会回收它。Java虚拟机宁愿抛出OutOfMemoryError异常,使程序异常终止,也不会回收具有强引用的对象来解决内存不足的问题。
软引用: 如果一个对象只具有软引用,当内存不够时,会回收这些对象的内存,回收后如果还是没有足够的内存,就会抛出OutOfMemoryError异常。Java提供了SoftReference类来实现软引用。
弱引用: 弱引用比起软引用具有更短的生命周期,垃圾收集器一旦发现了只具有弱引用的对象,不管当前内存是否足够,都会回收它的内存。Java提供了WeakReference类来实现弱引用。
虚引用: 虚引用并不会决定对象的生命周期,如果一个对象仅持有虚引用,这就和没有任何引用一样,在任何时候都可能被垃圾收集器回收。一个只具有虚引用的对象,被垃圾收集器回收时会收到一个系统通知,这也是虚引用的主要作用。Java提供了PhantomReference类来实现虚引用。
以上,了解jvm还需要大家了解以下算法:
引用计数算法
根搜索算法
标记-清除算法
复制算法
标记-压缩算法
分代收集算法
如果想象深入了解jvm内存管理建议还是Google下以上算法内容
关于Dalvik和ART虚拟机本片文章只做对jvm的简单对比。具体详细内容请产考老罗具体对其分析:推荐:https://www.kancloud.cn/alex_wsc/androids/401771
Dalvik
Dalvik是Google专门为Android操作系统开发的虚拟机。它支持.dex(即“Dalvik Executable”)格式的Java应用程序的运行。.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。Dalvik由Dan Bornstein编写,名字来源于他的祖先曾经居住过的小渔村达尔维克(Dalvík),位于冰岛。
Dalvik虚拟机,简称DVM。DVM是Google专门为Android平台开发的虚拟机,它运行在Android运行时库中。需要注意的是DVM并不是一个Java虚拟机。
DVM和JVM的区别 DVM之所以不是一个JVM ,主要原因是DVM并没有遵循JVM规范来实现。DVM与JVM主要有以下区别。
基于的架构不同:JAVA虚拟机基于 栈结构,程序在运行时虚拟机需要频繁的从栈上读取写入数据,这个过程需要更多的指令分派与内存访问次数,会耗费很多CPU时间。Dalvik虚拟机基于 寄存器架构,数据的访问通过寄存器间直接传递,这样的访问方式比基于栈方式要快很多。
基于栈的架构具有更好的可移植性,因为其实现不依赖于物理寄存器
基于栈的架构通常指令更短,因为其操作不需要指定操作数和结果的地址
基于寄存器的架构通常运行速度更快,因为有寄存器的支撑
基于寄存器的架构通常需要较少的指令来完成同样的运算,因为不需要进行压栈和出栈
执行的字节码不同:Java运行的是Java字节码,DVM运行的是Dalvik字节码。Java类会被编译成一个或多个.class文件,打包成jar文件,而后JVM会通过相应的.class文件和jar文件获取相应的字节码。而DVM会用dx工具将所有的.class文件转换为一个.dex文件,然后DVM会从该.dex文件读取指令和数据。当JVM加载该.jar文件的时候,会加载里面的所有的.class文件,JVM的这种加载方式很慢,对于内存有限的移动设备并不合适。
而在.apk文件中只包含了一个.dex文件,这个.dex文件里面将所有的.class里面所包含的信息全部整合在一起了,这样再加载就提高了速度。.class文件存在很多的冗余信息,dex工具会去除冗余信息,并把所有的.class文件整合到.dex文件中,减少了I/O操作,提高了类的查找速度。

class文件格式:

Dalvik可执行文件体积更小(原因同第二点)
DVM允许在有限的内存中同时运行多个进程:DVM经过优化,允许在有限的内存中同时运行多个进程。在Android中的每一个应用都运行在一个DVM实例中,每一个DVM实例都运行在一个独立的进程空间。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
ART虚拟机
ART(Android Runtime)是Android 4.4发布的,用来替换Dalvik虚拟,Android 4.4默认采用的还是DVM,系统会提供一个选项来开启ART。在Android 5.0时,默认采用ART,DVM从此退出历史舞台。
DVM中的应用每次运行时,字节码都需要通过即时编译器(JIT,just in time)转换为机器码,这会使得应用的运行效率降低。而在ART中,系统在安装应用时会进行一次预编译(AOT,ahead of time),将字节码预先编译成机器码并存储在本地,这样应用每次运行时就不需要执行编译了,运行效率也大大提升。
在不同平台DEX转化为ODEX的过程,如下图所示: 
从安装过程上来看 Java的代码实际上需要两次“转换”才可以在android设备上运行
一.PC端:.class->.dex->.apk
二.phone:dex->odex
区别在于第二步。
ART : .dex->.odex(机器码)(AOT Ahead-Of-Time) Dalvik: .dex->.odex(字节码)(JIT Just-In-Time)
机器码可直接执行,而字节码每次启动都需要执行将优化过的odex字节码再转换成机器码
ART优点:
应用运行更快,因为 DEX 字节码的翻译在应用安装是就已经完成。
减少应用的启动时间,因为直接执行的是 native 代码。
提高设备的续航能力,因为节约了用于一行一行解释字节码所需要的电池。
支持更低的硬件
ART缺点:
由于在安装时时生成的 native 机器码是存储在内部存储器上,所以需要更多的内部存储空间。(大概多个10%~20%)
应用安装需要更长的时间,因为 DEX 字节码需要在安装时就翻译成机器码。
本篇文章内容较长,主要时便于后期对android内存管理及优化打好基础,感兴趣的童鞋可以收藏慢慢看。
Last updated
Was this helpful?